Executive Summary
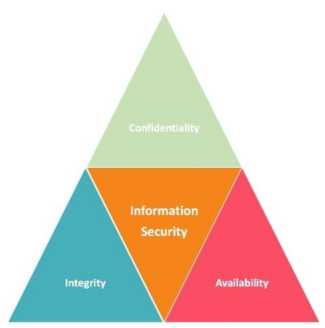
One of the main purposes of cybersecurity is to guarantee the properties of the CIA triad (Confidentiality, Integrity, and Availability) [1], also known as the CIA triangle of data and services (Figure 1). Confidentiality refers to the prevention of an information disclosure to unauthorized entities or individuals; integrity implies that data cannot be modified without detection, ensuring its correctness; and availability seeks to provide uninterrupted access to the system by legitimate users, whenever it is required. Hence, CIA properties become an important gear for information security. These properties are the security requirements that a computer system should accomplish, and they are directly linked to each other, so a balance between them guarantees high levels of security and trust.
As a consequence, a failure in any of these three properties can impact the rest of them, affecting the trust of the user on the system. As an example, the lack of confidentiality can lead to a high probability of integrity violation, and the modification of the integrity data can provoke applications to stop working in a proper way, affecting availability. In particular, one of the main issues we can face when it comes to the fulfilment of such properties is the existence of security vulnerabilities. This leads their detection and analysis to be crucial for ensuring the security and trustworthiness of the system.
More in particular, a security vulnerability is a weakness that can be exploited by an attacker in order to compromise the confidentiality, availability or integrity of a system. Nowadays, the number of vulnerabilities disclosed are increasing every year, and those that are present in widely-used systems can cause severe economic, reputational and even societal harms. Therefore, it is essential to identify these vulnerabilities on an early stage of the systems’ development life cycle, and improve the assessment processes and tools that allow to detect, classify, evaluate and mitigate vulnerabilities on an accurate manner.
As the first step of the vulnerability assessment process, the identification is critical. In this sense, substantial research has been devoted to techniques that analyse source code in order to detect and characterize security vulnerabilities [2], but also to evaluate how a vulnerability could propagate to other elements of the software supply chain [e.g., 3, 4]. In BIECO project, the vulnerability identification and characterization process will focus mainly on three topics:
- Detection: it consists on the accurate identification of software vulnerabilities within a source code. For this purpose, BIECO will explore the use of Machine Learning and data mining techniques, such as anomaly detection-based techniques [e.g., 5, 6], vulnerable code pattern recognition [e.g., 7, 8] and vulnerability prediction models [e.g., 9, 10].
- Forecasting: it allows to make predictions of future data on time series domain, i.e., where data are collected at regular intervals over time (e.g., hourly, daily, monthly, annually). In the context of BIECO, the idea is two-fold: i) forecasting the number of vulnerabilities [e.g., 11, 12, 13] and ii) forecasting the period of time in which these vulnerabilities could be exploited (e.g., within the next 12 months) [e.g., 14, 15].
- Propagation: it offers an estimation of how a localized vulnerability can affect the rest of the code. For this purpose, studies based on graph theory will be analysed [e.g., 16, 17], as well as optimization path algorithms such as Ant Colony Optimization (ACO) [18, 19]. Moreover, the applicability of the recent standard Manufacturer Usage Description (MUD) will be also assessed.
In particular, this document provides a review on the current state of the art about vulnerabilities assessment related to the three topics mentioned before (detection, forecasting and propagation). The deliverable starts with an introduction to the concept of security vulnerabilities and continues with a summary of the most representative standards in the field, as well as a compilation of vulnerability datasets, including the NVD (National Vulnerability Database)[1]. The document presents then a review of several state-of-the-art techniques for the assessment of software vulnerabilities, including their identification, forecasting and propagation. Finally, some conclusions are provided in order to summarize the most important reviewed topics.
Project Summary
Nowadays most of the ICT solutions developed by companies require the integration or collaboration with other ICT components, which are typically developed by third parties. Even though this kind of procedures are key in order to maintain productivity and competitiveness, the fragmentation of the supply chain can pose a high risk regarding security, as in most of the cases there is no way to verify if these other solutions have vulnerabilities or if they have been built taking into account the best security practices. In order to deal with these issues, it is important that companies make a change on their mindset, assuming an “untrusted by default” position. According to a recent study only 29% of IT business know that their ecosystem partners are compliant and resilient with regard to security. However, cybersecurity attacks have a high economic impact and it is not enough to rely only on trust. ICT components need to be able to provide verifiable guarantees regarding their security and privacy properties. It is also imperative to detect more accurately vulnerabilities from ICT components and understand how they can propagate over the supply chain and impact on ICT ecosystems. However, it is well known that most of the vulnerabilities can remain undetected for years, so it is necessary to provide advanced tools for guaranteeing resilience and also better mitigation strategies, as cybersecurity incidents will happen. Finally, it is necessary to expand the horizons of the current risk assessment and auditing processes, taking into account a much wider threat landscape. BIECO is a holistic framework that will provide these mechanisms in order to help companies to understand and manage the cybersecurity risks and threats they are subject to when they become part of the ICT supply chain. The framework, composed by a set of tools and methodologies, will address the challenges related to vulnerability management, resilience, and auditing of complex systems.
1. Introduction
1.1. Motivation
In recent years, an alarming increase in cybersecurity attacks has been detected[1]. Especially with the COVID pandemic, where teleworking is the new lifestyle, attackers have at their disposal a huge and often insufficiently protected attack surface. One of the best-known examples is the WannaCry ransomware, which affected more than 230,000 computers in 150 countries. The most affected countries were Russia; Ukraine; India; Great Britain, where the National Health Service was compromised; Spain, for the attack on Telefonica and Germany, where the German railway company Deutsche Bahn AG was the main target. Cyber attackers collected more than 140,000 dollars in bitcoins.
This is causing companies huge economic losses, service interruptions and great social concern. These attacks damage the company’s reputation, causing customers to be lost. In addition to the security of information systems, such as firewall mechanisms to prevent DDoS attacks, organizations must focus on the development of their software applications. According to the IBM security summit in 2016, 60% of cyberattacks benefits from inside[2], benefiting from bugs.
Bugs are nothing more than programming errors, and most of them are completely harmless beyond affecting the performance of the product. However, some bugs can be exploited by malicious external entities, in order to obtain certain benefits (private data, access to the system, interruption of the service, etc.). In this case we are no longer talking about bugs, but about vulnerabilities and weaknesses.
Taking into account the impact that a simple vulnerability can have, it is essential to further research and improve the existent vulnerability assessment mechanisms. This document presents a review on state-of-the-art techniques for vulnerability assessment, as well as a compilation of relevant vulnerability related standards and databases. The results of this review will be used as an input for the design and development of the vulnerability assessment tools that will be produced by the WP3 of the BIECO project.
1.2. Background
A security vulnerability is defined by the European Union Agency for Cybersecurity (ENISA)[1]as a weakness an adversary could take advantage of to compromise the confidentiality, availability, or integrity of a resource. At the same time, a weakness refers to implementation flaws or security implications due to design choices. For example, a lack of control over the length of the data entered could lead to a buffer overflow vulnerability, allowing attackers to steal or corrupt private information, or even run malicious code.
An added problem is the propagation of vulnerabilities either within the same component or between different components. Although a certain functionality can be designed in a secure way, the reality is that its interaction with a vulnerable functionality or component can make the entire product insecure. An example is the one that we can find within the Maven project, where the POM file in org.wso2.carbon.security.policy has a dependency with components from org.apache.derby. This dependency provokes that vulnerabilities existing in org.apache.derby,
such as CVE-2015-1832, can cause potential vulnerability threats in the Maven project. Therefore, it is not only necessary to detect and correct the vulnerabilities of our component in an isolated way, but also to analyse the possible consequences derived from the propagation of vulnerabilities coming from another component.
Vulnerability management arises as a way to identify, classify, evaluate and mitigate vulnerabilities. Following the definition from ENISA, vulnerability management comprises several steps:
• Preparation: defining the scope of the vulnerability management process.
• Vulnerability scanning: vulnerability scanners are automated tools that scan a system for known security vulnerabilities providing a report with all the identified vulnerabilities sorted based on their severity.
• Identification, classification and evaluation of the vulnerabilities: the vulnerability scanner provides a report of the identified vulnerabilities.
• Remediating actions: the asset owner determines which of the vulnerabilities will be mitigated.
• Rescan: once the remediating actions are completed, a rescan is performed to verify their effectiveness.
This document presents an overview of the state of the art regarding vulnerability assessment and, in particular, it focuses on the review of vulnerability scanning methods based mainly on Artificial Intelligence techniques. Section 2 introduces the main standards that can be used to structure vulnerabilities information, as well as a summary of the main databases that contain information for their characterization. Section 3 reviews the main techniques for vulnerability detection (i.e., scanning), paying special attention to the techniques based on anomaly detection, patterns and prediction models. After that, Section 4 reviews the main techniques for forecasting, which aim to give an estimation on the number of vulnerabilities that could arise and the probability of their exploitation in a certain period of time, whereas Section 5 focuses on the vulnerability propagation analysis techniques, as well as the applicability of the recent standard Manufacturer Usage Description (MUD) for vulnerability assessment. Finally, the document ends with a summary of the conclusions.
2. Analysis of Vulnerability Public Information
This section presents different types of information that are essential in order to characterize adequately a security vulnerability and, therefore, that should be taken into account during the design and development of BIECO’s vulnerability assessment tools. The section includes a selection of relevant vulnerability standards, a compilation of vulnerability datasets, as well as other vulnerability compilation projects.
A vulnerability assessment process can be significantly difficult without a common baseline. Therefore, when dealing with vulnerabilities, it is important to take into account the most common standards in the fields (subsection 2.1). Having a structured information about vulnerabilities simplifies their assessment process, providing a common understanding of the context of which the different vulnerabilities are discovered.
As the standardization in the vulnerability field has become more mature, several vulnerability databases have emerged. These databases are just data repositories, typically public, that compile software and hardware vulnerabilities information. To date, there have been published several databases that can be used as a support for the assessment of vulnerabilities, and that provide users with different types of information. Subsection 2.2 will review the most relevant vulnerability databases, paying special attention to National Vulnerability Database (NVD)[1].
Finally, subsection 2.3 introduces OWASP, a reference project that compiles some of the most relevant vulnerabilities.
2.1. Vulnerability Standards
In this subsection we present a selection of vulnerability related standards, such as Common Vulnerabilities and Exposures (CVE), Common Weakness Enumeration (CWE), Common Platform Enumeration (CPE) and Common Vulnerability Scoring System (CVSS). All of them are well-known and widespread standards: from identifying vulnerabilities (CVE), to describing common weaknesses in software (CWE), to providing consistent names for referring to operating systems, hardware and applications (CPE), up to the rating of the severity of vulnerabilities (CVSS).
2.1.1. Common Vulnerabilities and Exposures (CVE)
Common Vulnerabilities and Exposures (CVE) is a list of records of public known information about security vulnerabilities, widely used by multiple IT vendors. Its identifiers (CVE-YYYY- XXXX) enable a common understanding about vulnerabilities and help with the evaluation of the coverage of vulnerability tools and services. CVE is the industry standard for vulnerability and exposure identifiers whose records provide reference points for data exchange so that cybersecurity products and services can speak with each other. Products and services compatible with CVE provide easier interoperability, and enhanced security.
The CVE List feeds the NVD or National Vulnerability Database (see section 2.2.1), which then builds upon the information included in CVE Records to provide enhanced information for each record such as fix information, severity scores, and impact ratings.
2.1.2. Common Weakness Enumeration (CWE)
Common Weakness Enumeration (CWE) is a dictionary of unique identifiers of common software weaknesses (also hardware weaknesses from 2020). This project is supported by the U.S. Department of Homeland Security (DHS) Cybersecurity and Infrastructure Security Agency (CISA), the Homeland Security Systems Engineering and the Development Institute (HSSEDI), which is operated by The MITRE Corporation.
It offers a wealth of options that can describe common weaknesses such as detection methods, consequences, affected resources and likelihood. Even though CWE seems to be related to CVE, CWE does not deal with specific software vulnerabilities. For example, CWE would describe a buffer overflow in multiple software types, but a CVE ID would be assigned to one specific buffer overflow vulnerability in Cisco IOS version X.
Nonetheless, CWE is useful for:
• Describing and discussing software and hardware weaknesses in a common language.
• Checking for weaknesses in existing software and hardware products.
• Leveraging a common baseline standard for weakness identification, mitigation, and prevention efforts.
• Preventing software and hardware vulnerabilities prior to deployment.
2.1.3. Common Platform Enumeration (CPE)
Common Platform Enumeration (CPE) is a structured naming scheme for information technology systems, software and packages. Based upon the generic syntax for Uniform Resource Identifiers (URI), CPE includes a formal name format, a method for checking names against a system and a description format for binding text and tests to a name.
The CPE dictionary contains the official list of CPE names. The dictionary is provided in XML format, which follows the CPE XML schema. In particular a typical CPE name would follow the structure cpe:/{part}:{vendor}:{product}:{version}:{update}:{edition}:{language}. In the context of vulnerability assessment, the CPE allows to identify unequivocally within a CVE the software and version that is affected by the vulnerability.
2.1.4. Common Vulnerability Scoring System (CVSS)
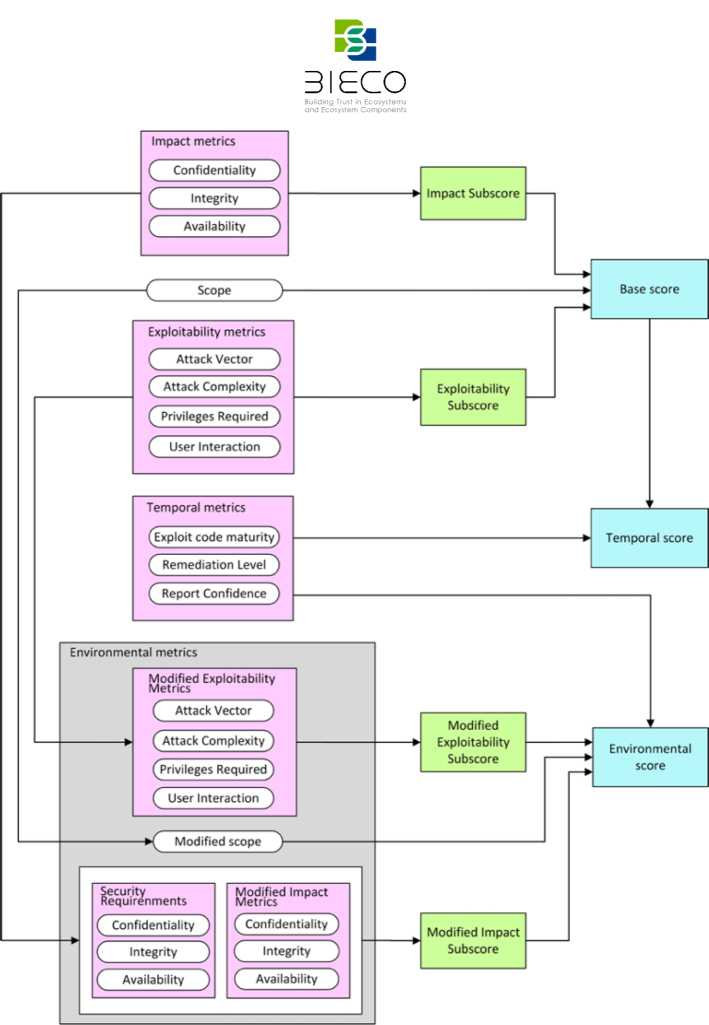
Common Vulnerability Scoring System (CVSS) is a free and open industry standard for assessing the severity of a security vulnerability. The standard provides a way to capture and understand the principal characteristics of a vulnerability by means of assigning severity scores. These scores, which can take a value on the range from 0 to 10 (being 10 the most severe), are calculated based on a multi-formula process that depends on several metrics.
Historically, vendors have used their own methods for scoring software vulnerabilities, usually without detailing their criteria or processes. This creates a major problem for users, particularly those who manage disparate IT systems and applications. In this sense, the goal for CVSS is to facilitate the generation of consistent scores that accurately represent the impact of vulnerabilities, as it provides full details regarding the parameters used to generate each score. The first version of CVSS was released in 2005, version 2 was released in 2007 and version 3 in 2015. The current version is 3.1. It was released in 2019. The CVSS is calculated from three metrics groups, i.e., Base, Temporal, and Environmental. Each of these metrics are calculated taking into account a set of sub scores obtained from several features. This process is explained in subsection 2.1.4.4 and the metrics groups are detailed below.
2.1.4.1. Basic Metrics
These set of metrics reflect the severity of vulnerabilities according to their characteristics and assumes the worst-case impact across different environments. Base metrics do not change over time and are common to all environments. For a better understanding of the vulnerability, base metric is divided in three subtypes, Exploitability metrics, Scope metric and Impact metrics, which, in turn, are made up of a set of metrics.
The Exploitability metrics represent the characteristics of a vulnerable component, and reflect the technical means by which the vulnerability can be exploited. This metric is composed of four features:
- Attack Vector reflects the context by which vulnerability exploitation is possible. Its value is greater the more distant an attacker can be to exploit the vulnerable component. The possible values (and sub scores) of Attack Vector are:
• Network (0.85) if the vulnerable component is bound to the network stack and the set of possible attackers extends up to the entire Internet.
• Adjacent (0.62) if the attack is limited at the protocol level to a logically adjacent topology. An attack must be launched from the same physical or logical network.
• Local (0.55) if the vulnerable component is not bound to the network stack. The attacker must access the target system locally or remotely (e.g., Telnet, SSH), or interact with another person to perform the required actions, using social engineering techniques.
• Physical (0.2) if the attack requires the physical touch or manipulation of the vulnerable component. - Attack Complexity represents the conditions beyond the attacker’s control that must exist in order to exploit the vulnerability. The possible values (and sub scores) are:
• Low (0.77) if specialized access conditions or extenuating circumstances do not exist. Repeatable success can be expected.
• High (0.44) if successful attack requires certain preparation operations performed against the vulnerable component. - Privileges Required describes the level of privileges an attacker must possess before successfully exploiting the vulnerability. The possible values (and sub scores) are:
• None (0.85) if no access to settings or files of the vulnerable component is required to carry out an attack.
• Low (0.62 if the Scope metric value is Unchanged, or 0.68 if it is Changed) if an attack requires privileges that provide basic user capabilities that affect only settings and files owned by a user.
• High (0.27 if the Scope metric value is Unchanged, or 0.5 if it is Changed) if an attack requires privileges that provide significant (e.g., administrative) control over the vulnerable component, allowing access to component-wide settings and files.
- User Interaction captures the requirement for a human user, other than the attacker, to participate in the successful compromise of the vulnerable component. The possible values (and sub scores) are:
• None (0.85) if no interaction from any user is required to exploit the vulnerability.
• Required (0.62) if user action is required for vulnerability exploitation.
The Scope metric indicates whether a vulnerability in one vulnerable component impacts resources in components beyond its security scope. The security scope of a component encompasses other components that provide functionality solely to that component, even if these other components have their own security authority. The possible values are:
• Unchanged if an exploited vulnerability can only affect resources managed by the same security authority.
• Changed if an exploited vulnerability can affect resources beyond the security scope managed by the security authority of the vulnerable component.
The Impact metric reflects the consequence of a successful exploit over the impacted component, which could be a software application, a hardware device or a network resource. The metric is composed of three groups:
- Confidentiality measures the impact to the confidentiality of the information resources managed by a software component, due to a successfully exploited vulnerability. The possible values (and sub scores) are:
• High (0.56) if there is a serious loss of confidentiality, resulting in all or some of the resources within the impacted component being divulged to the attacker.
• Low (0.22) if there is some loss of confidentiality, but the attacker does not have control over what information is obtained and the attack does not cause a direct, serious loss to the impacted component.
• None (0) if there is no loss of confidentiality within the impacted component. - Integrity measures the impact of a successfully exploited vulnerability to the trustworthiness and veracity of information. The possible values (and sub scores) are:
• High (0.56) if there is a serious loss of integrity, or a complete loss of protection. A successful attack can modify protected files, resulting a serious consequence to the impacted component.
• Low (0.22) if modification of data is possible, but there is no control over the consequences, or the amount of modification is limited. The modifications have a partial effect on the impacted component.
• None (0) if there is no loss of integrity within the impacted component. - Availability measures the impact to the availability of the impacted component resulting from a successfully exploited vulnerability. The possible values (and sub scores) are:
• High (0.56) if a successful attack can fully or partially deny access to resources, presenting a serious consequence to the impacted component. The loss can be either sustained (during the attack) or persistent if the condition persists after the attack has completed.
• Low (0.22) if a successful attack can reduce performance or cause interruptions in resource availability but overall, there is no serious consequence to the impacted component, there is no complete denial of service to legitimate users.
• None (0) if there is no impact to availability within the impacted component.